
自己接下来的科研应该会偏向DFT方向(虽然具体课题还没确定),总之还是得尽快补充知识。
Kohn-Sham Inversion问题,简单来说就是如何在已知基态电子密度$\rho (r)$的前提下,求解KS方程中的等效势分布$v_{eff}(r)$。以下是两篇论文提出的启发性方法。
1. Zhao-Morrison-Parr method [1]
1.1 $v_{xc}$的自洽求解
经典的 KS 方程为
\[\left[ -\frac{1}{2}\nabla^2 + v_{\text{ext}}(\mathbf{r})+ v_{\text{H}}(\mathbf{r})+ v_{\text{xc}}(\mathbf{r}) \right] \phi_i = \varepsilon_i \phi_i\]这个方程使用自洽法进行求解,但由于$v_{xc}$的形式未知,我们始终无法收敛到真正精确的密度解。现在如果我们转换思路,如果通过实验等手段得到密度分布$n(r)$,是否有可能数值求解得到$v_{xc}(r)$的分布。
简单的思路是同样找一个能够自洽求解的交换相关势$v_{xc}[n(r),n_{tar}(r)]$,使得迭代过程中解出的波函数$\phi_i(\mathbf{r})$能够逐渐满足约束
\[\sum_{i=1}^N |\phi_i(\mathbf{r})|^2 = \rho_0(\mathbf{r})\]ZMP方法最初按照这个设想,有如下的构造
\[\left[ -\frac{1}{2}\nabla^2 + v_{ext}(\mathbf{r}) + v_c^\lambda(\mathbf{r}) \right] \phi_i^\lambda = \varepsilon_i^\lambda \phi_i^\lambda\]其中$v_c^\lambda(\mathbf{r})$是平均场相互作用能和交换相关能之和,这里直接将二者视作一个整体作为泛函。
\[v_c^\lambda(\mathbf{r}) = \lambda \int \frac{\rho(\mathbf{r}') - \rho_0(\mathbf{r}')}{|\mathbf{r} - \mathbf{r}'|} d\mathbf{r}'\]直观理解,对一个固定的$\lambda$,肯定都能通过自洽求解得到最终收敛的波函数$\phi_i^\lambda(\mathbf{r})$以及对应的电子密度$\rho^\lambda(\mathbf{r})$。且随着$\lambda$的增大,$\rho^\lambda(\mathbf{r})$一定会趋于给定的真实密度$\rho_0^\lambda(\mathbf{r})$,以保证总能量不会爆炸。最后通过外推法令$\lambda \rightarrow \infty$不难得到势函数$v_c^\lambda(\mathbf{r})$的数值分布形式。
这个想法倒是没什么问题,但有一个小细节需要优化。既然把电子相互作用的能量等效到一个函数$v_{c}$上,那这个函数必然在远处符合$\sim \frac{N-1}{r}$的衰减形式(即扣除电子自身后的静电势能),这个衰减并不算快,这意味着函数必须在原处也要有比较好的拟合,因此意味着迭代收敛速度会很慢。
论文提出的改进方法将自洽求解方程变成下面的形式
\[\left[ -\frac{1}{2}\nabla^2 + v_{ext}(\mathbf{r}) + \left(1 - \frac{1}{N}\right)v_H(\mathbf{r}) + v_c^\lambda(\mathbf{r}) \right] \phi_i^\lambda(\mathbf{r}) = \varepsilon_i^\lambda \phi_i^\lambda(\mathbf{r})\]这里的 $\left(1 - \frac{1}{N}\right)v_J(\mathbf{r})$ 即为 Fermi-Amaldi 项。可以看作是(不严谨地)考虑了自相互作用的Hartree势。这么修正后$v_c^\lambda(\mathbf{r})$的衰减速度就会快得多,迭代时更多的优化可以体现在关键的近域部分。
对照标准的 KS 方程,可以得到精确交换相关势的数学表达式
\[v_{\text{xc}}(\mathbf{r}) = \lim_{\lambda \to \infty} \left[ v_c^\lambda(\mathbf{r}) - \frac{1}{N}v_J^\lambda(\mathbf{r}) \right]\]实际计算中,会通过对一系列大 $\lambda$的结果,对自变量 $1/\lambda \to 0$ 进行多项式外推,从而精确锁定 $v_{\text{xc}}(\mathbf{r})$。
1.2 $E_{xc}$的非局域性证明
虽然有些偏题,但论文中有一个有趣的理论证明,这里一并放上。
试证:KS理论中的交换相关能泛函$E_{\text{xc}}[\rho]$能否写成定域(Local)形式,即只依赖于某一点的密度值\(E_{\text{local}}[n] = \int f(n(\mathbf{r})) d\mathbf{r}\)
设 $Q[\rho] = \int f(\rho) d\mathbf{r}$ 是一个严格的定域泛函。由于其空间各点独立,对其求变分
\[v_Q(\mathbf{r}) = \frac{\delta Q}{\delta \rho} = \frac{df(\rho)}{d\rho}\]$f$关于径向坐标 $r$ 的导数为
\[\frac{df(\rho)}{dr} = \frac{df(\rho)}{d\rho} \cdot \frac{d\rho}{dr} = v_Q(\mathbf{r}) \frac{d\rho}{dr}\]对球对称原子系统,将泛函 $Q$ 在球坐标下展开
\[Q = \int f(\rho) r^2 dr d\Omega\]为了使用分布积分,设定:
\[u = f(\rho) \implies du = \frac{df}{dr}dr = v_Q \frac{d\rho}{dr} dr\] \[dv = r^2 dr \implies v = \frac{1}{3}r^3\]当 $r \to \infty$ 时,电子密度 $\rho \to 0$,导致 $f(\rho) \to 0$。因此边界项 $[uv]_0^\infty$ 严格为 0。代入分部积分公式
\[Q = 0 - \int \left( \frac{1}{3}r^3 \right) \left( v_Q(\mathbf{r}) \frac{d\rho}{dr} \right) dr d\Omega\] \[Q = -\frac{1}{3} \int v_Q(\mathbf{r}) \cdot r \cdot \left( \frac{d\rho}{dr} \right) \underline{r^2 dr d\Omega} = -\frac{1}{3} \int v_Q(\mathbf{r}) \cdot r \cdot \frac{d\rho}{dr} d\mathbf{r}\]若令 $Q = E_{\text{xc}}$,则其导数 $v_Q = v_{\text{xc}}$。若 $E_{\text{xc}}$ 是定域的,上式必须强行成立。根据定义
\[E_{xc}[n] \equiv (T[n] - T_s[n]) + (V_{ee}[n] - E_H[n])\]我们知道,$E$ 和 $T$ 是不依赖任何密度泛函理论的、纯粹的物理真实值。因此完全可以对比真实值和高精度模拟结果以验证局域性的正误
根据论文,二者数值差异很大,否定了局域性假设,这也在意料之内。
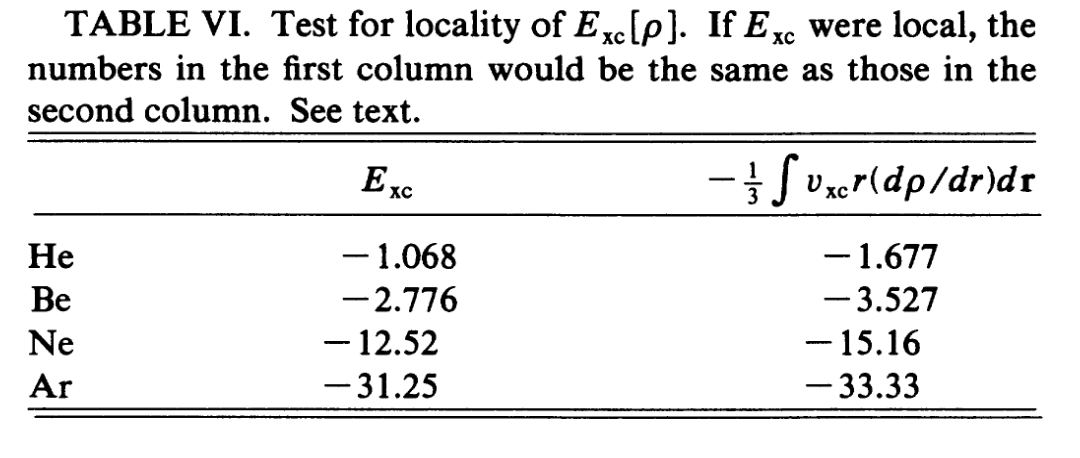
2. Wu-Yang method [2]
2.1 基本原理
自洽场迭代求解虽然听起来合理,但其实细想一下还是有不少问题的。在最优化理论中,要100%保证算法能收敛到全局唯一解,目标泛函必须在全空间具有严格的凹性或凸性。自洽能不能收敛,我们是没法证明的。甚至在实际的计算机数值计算中,ZMP 方法常常会遇到严重的收敛困难,甚至发散。
而且就算能收敛,迭代次数往往也不容乐观。
因此相较于ZMP的自洽法,WY方法提出了一种更加简单直接的思路,也就是把目标势函数进行一组高斯基函数的线性展开。将待求的总势能 $v(\mathbf{r})$ 拆分为三部分
\[v(\mathbf{r}) = v_{\text{ext}}(\mathbf{r}) + v_0(\mathbf{r}) + v_t(\mathbf{r}) = v_{\text{ext}}(\mathbf{r}) + v_0(\mathbf{r}) + \sum_t b_t g_t(\mathbf{r})\]与ZMP类似的采用了具有自相互作用修正的 Fermi-Amaldi 势
\[v_0(\mathbf{r}) = \frac{N-1}{N} \int \frac{\rho_{\text{in}}(\mathbf{r}')}{|\mathbf{r} - \mathbf{r}'|} d\mathbf{r}'\]$\sum_t b_t g_t(\mathbf{r})$则是需要优化的部分。WY方法用一组已知的高斯基函数 ${g_t(\mathbf{r})}$ 将其线性展开。此时,优化一个连续场的问题,简化为了求解一组有限维度的线性系数标量 ${b_t}$。
理论上无限维的高斯基函数是完备的,但实际运用只能使用有限个基函数,在所需的精度上进行近似。
这里的设计其实很有巧思,因为总势能$v(\mathbf{r})$本身是没法用高斯基组展开的,必须扣除有奇点的$v_{\text{ext}}(\mathbf{r})$,再扣除$v_0(\mathbf{r})$确保边界快速收敛,剩下的有限平滑的函数才能用高斯基组进行高精度的近似。
于是剩下的问题就是有限参量${b_t}$的全局优化问题,这里有一个很有意思的问题转换,我们构造泛函
\[W_s[v(\mathbf{r})] = E_s[v] - \int v(\mathbf{r})\rho_{\text{in}}(\mathbf{r}) d\mathbf{r}\]也即
\[W_s[v(\mathbf{r})] = \langle \Psi_v | \hat{T} | \Psi_v \rangle + \int v(\mathbf{r}) [ \rho_v(\mathbf{r}) - \rho_{\text{in}}(\mathbf{r}) ] d\mathbf{r}\]现在我们尝试证明一个引理。现在,假设算法闭着眼睛摸索到了一个错误的外部势能 $v_{\text{wrong}}(\mathbf{r})$。 在 $v_{\text{wrong}}$ 下,它能解出一个基态波函数 $\Psi_{\text{wrong}}$,以及相应的电子密度 $\rho_{\text{wrong}}$。
我们需要证明
\[W_s[v_{\text{wrong}}] \le W_s[v_{\text{true}}]\]根据定义
\[W_s[v_{\text{wrong}}] = \min_{\Psi} \left\{ \langle \Psi | \hat{T} + \hat{V}_{\text{wrong}} | \Psi \rangle \right\} - \int v_{\text{wrong}}(\mathbf{r})\rho_{\text{in}}(\mathbf{r}) d\mathbf{r}\]根据变分原理,如果我们偏偏把那个正确的波函数 $\Psi_{\text{true}}$ 代入这个错误的哈密顿量呢?它算出来的能量必定比基态高
\[\min_{\Psi} \left\{ \langle \Psi | \hat{T} + \hat{V}_{\text{wrong}} | \Psi \rangle \right\} \le \langle \Psi_{\text{true}} | \hat{T} + \hat{V}_{\text{wrong}} | \Psi_{\text{true}} \rangle\]把右边展开
\[\langle \Psi_{\text{true}} | \hat{T} + \hat{V}_{\text{wrong}} | \Psi_{\text{true}} \rangle = \langle \Psi_{\text{true}} | \hat{T} | \Psi_{\text{true}} \rangle + \int v_{\text{wrong}}(\mathbf{r})\rho_{\text{in}}(\mathbf{r}) d\mathbf{r}\]把这个不等式带回 $W_s[v_{\text{wrong}}]$ 的表达式中
\[W_s[v_{\text{wrong}}] \le \left( \langle \Psi_{\text{true}} | \hat{T} | \Psi_{\text{true}} \rangle + \int v_{\text{wrong}}(\mathbf{r})\rho_{\text{in}}(\mathbf{r}) d\mathbf{r} \right) - \int v_{\text{wrong}}(\mathbf{r})\rho_{\text{in}}(\mathbf{r}) d\mathbf{r}\]于是命题得证
\[W_s[v_{\text{wrong}}] \le \langle \Psi_{\text{true}} | \hat{T} | \Psi_{\text{true}} \rangle = W_s[v_{\text{true}}]\]因此现在问题被我们转化为一个变分问题,当$v(\mathbf{r}) \rightarrow v_{\text{true}}$,泛函$W_s[v(\mathbf{r})]$取得极大值。
由于$v(\mathbf{r})$可变参数是系数向量 $\mathbf{b} = {b_t}$,泛函 $W_s[v]$ 可转化为普通的多元标量函数 $W_s(\mathbf{b})$。因此其导数存在解析形式。
- 梯度向量
- Hessian 矩阵
拥有了完全解析的二阶 Hessian 矩阵,意味着算法可以使用最直接的二阶牛顿法
\[\mathbf{b}^{(k+1)} = \mathbf{b}^{(k)} - \mathbf{H}^{-1} \mathbf{G}\]这种方法的迭代速度就比ZMP快得多(毕竟优化的参数就那么多)。
另外,如果需要回推交换相关势$v_{xc}(\mathbf{r})$,根据 Kohn-Sham 标准有效势的定义:$v_{\text{eff}}(\mathbf{r}) = v_{\text{ext}}(\mathbf{r}) + v_H(\mathbf{r}) + v_{\text{xc}}(\mathbf{r})$。由于优化得到的精确有效势为 $v(\mathbf{r}) = v_{\text{ext}} + v_0 + \sum_t b_t g_t$,两式相对照
\[v_{\text{xc}}(\mathbf{r}) = \sum_t b_t g_t(\mathbf{r}) + v_0(\mathbf{r}) - v_H(\mathbf{r})\]也即
\[v_{\text{xc}}(\mathbf{r}) = \sum_t b_t g_t(\mathbf{r}) + \int \frac{\rho_{\text{in}}(\mathbf{r}') - \rho_v(\mathbf{r}')}{|\mathbf{r}-\mathbf{r}'|} d\mathbf{r}' - \frac{1}{N}\int \frac{\rho_{\text{in}}(\mathbf{r}')}{|\mathbf{r}-\mathbf{r}'|} d\mathbf{r}'\]2.2 Lieb变换与凹泛函证明
以上。
[1] Q. Zhao, R. C. Morrison, and R. G. Parr, Phys. Rev. A. 50, 2138 (1994).



