
很喜欢在写笔记的时候单曲循环一首歌,然后把这首歌的专辑封面当作笔记封面。
Ferminet由2020 DeepMind在PRR的论文《Ab initio solution of the many-electron Schrödinger equation with deep neural networks》提出,核心思想是用神经网络作为VMC拟设,发挥神经网络的高维度学习能力,试图彻底解决VMC最重要的拟设函数形式问题。
这篇笔记基本参照论文的结构来写,但为了不显得自己只是在复述,会尽可能重视数学上的推理,文字上会尽量简洁。[1]
1. Ferminet基本架构
简单的说,既然Ferminet的定位是波函数$\Psi(x_1,x_2…x_N)$的拟设,其本质自然就是一个高维度的拟合器。给定外势后,网络的输入是电子的坐标$x_i$(空间坐标$r_i$+自旋坐标$s_i$),输出是对应的波函数数值(显然,是未归一化的)
分三部分拆解一下整个网络架构,每个部分构造都很有亮点,很难说哪个是最核心的。
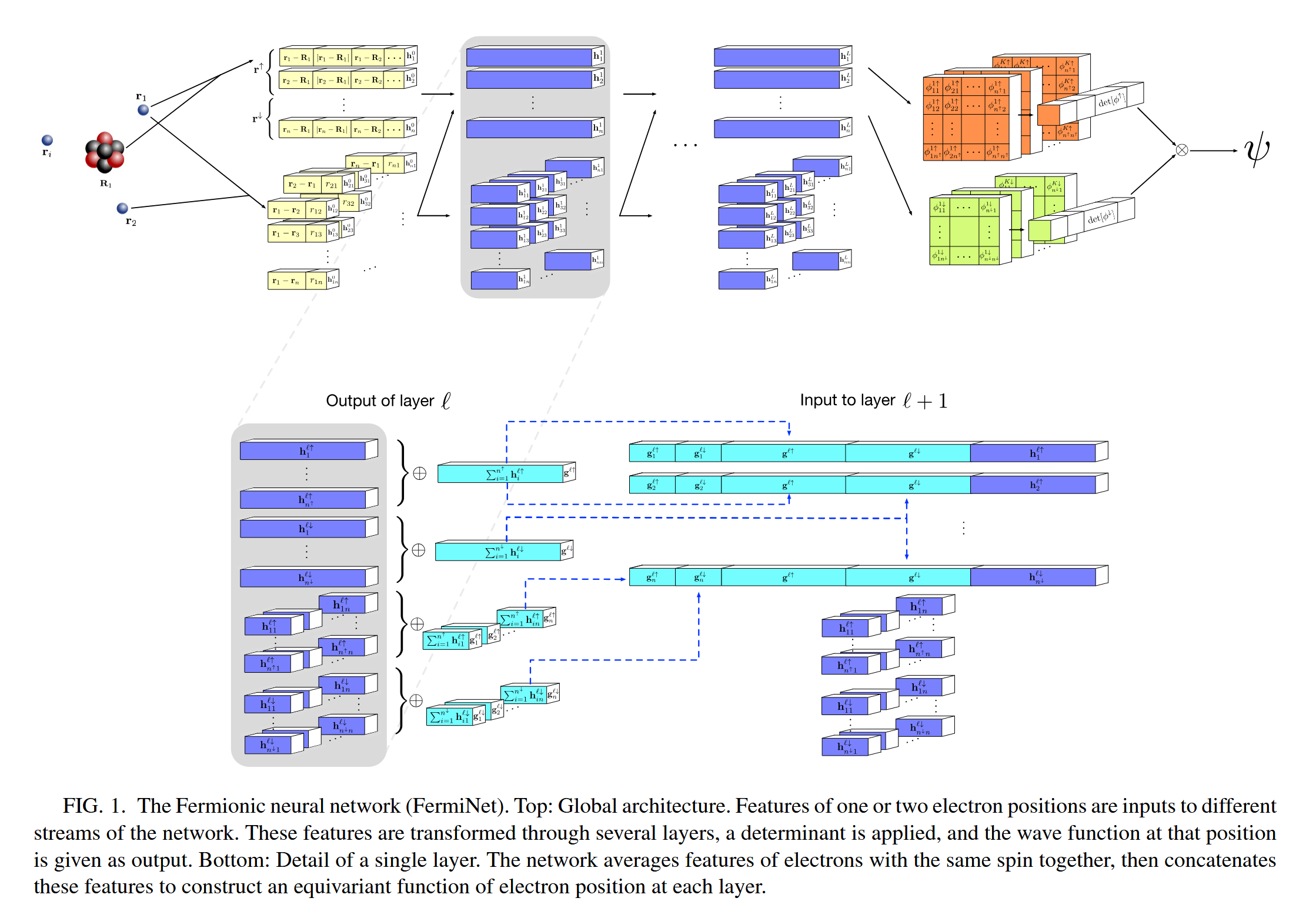
1.1 Input Layer
先看输入层,为了同时高效捕捉“电子-原子核”以及“电子-电子”之间的相互作用,FermiNet 设计了两个并行的特征作为输入的参数(也就是网络学习的基本特征量)
-
单电子流(Single-electron stream): 输入第 $i$ 个电子到各个原子核 $I$ 的相对位移向量 $(r_i - R_I)$ 以及绝对距离 $|r_i - R_I|$ 。
-
双电子流(Two-electron stream): 输入每对电子 $(i, j)$ 之间的相对位移向量 $(r_i - r_j)$ 以及绝对距离 $|r_i - r_j|$ 。
| 把绝对距离 $ | r_i - r_j | $ 直接作为输入送入网络这一点很重要,这一种显式的输入其实算是强调这一特征的学习。由于距离函数在零点是不光滑的,深度网络可以通过非线性变换直接模拟出波函数在粒子接触时的尖峰(Cusps)行为,从而省去了显式的 Jastrow 因子 。 |
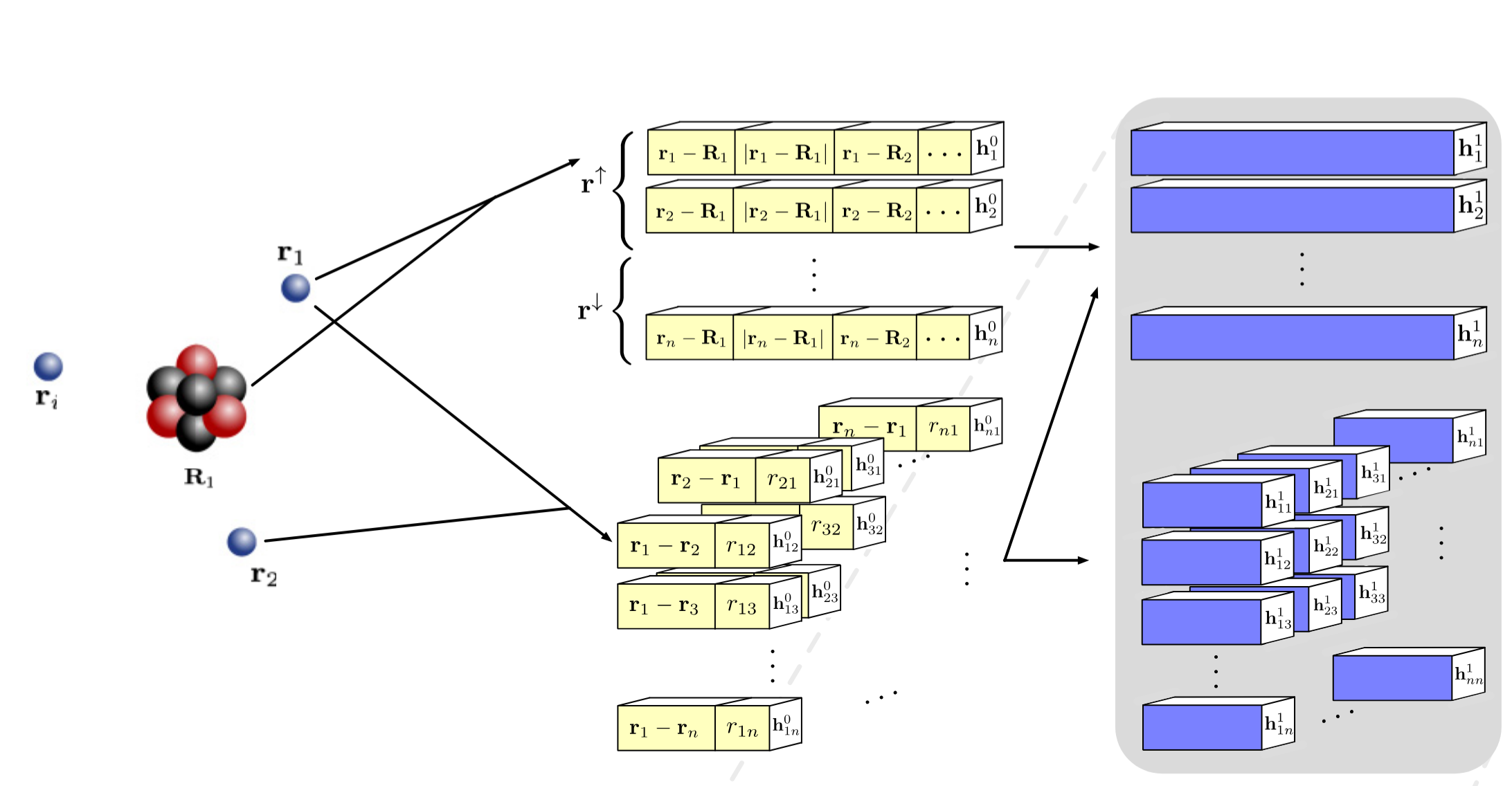
1.2 Hidden Layer
这一层的构造有许多要点。首先,我们知道整个网络是必须满足反对性的。即拟合的神经网络应该满足
\[\Psi(x_1...x_i,x_j...x_N)=-\Psi(x_1...x_j,x_i...x_N)\]虽然在Output Layer中有一个Slater行列式,但仍然需要满足行列式中的单元会随着坐标的交换而交换,如果使用简单的全连接网络肯定会完蛋,因为最后输出的单元不可分辨。
也就是说,若交换任意两个输入电子,其在中间层对应的特征向量应该仅仅发生位置对调,而特征内容保持一致 。为了满足这种置换等变性(Permutation Equivariance),中间层绝对不能使用像全连接层(对输入顺序敏感)或卷积层(对空间绝对位置敏感)那样的常规连接,而必须采用平移不变的聚合算子,例如求平均(Mean)。
FermiNet 的中间层(假设为第 $l$ 层)同样包含两组并行的特征流动,这两组流动通过特定的池化操作进行交叉耦合:
-
单电子流(Single-electron stream):第 $l$ 层的输出记为 $h_i^l$,它代表第 $i$ 个电子在当前层被提取出的高维特征向量。
-
双电子流(Two-electron stream):第 $l$ 层的输出记为 $h_{ij}^l$,它代表电子对 $(i, j)$ 在当前层被提取出的高维特征向量。
同时,由于体系中存在自旋向上($\uparrow$)和自旋向下($\downarrow$)两种电子,网络会对这两组电子分别进行聚合。
在第 $l$ 层向第 $l+1$ 层演进时,为了让第 $i$ 个电子知道其他电子的状态,网络会计算四种不同的均值向量。
| 特征类型 \ 自旋方向 | 上自旋 ($\uparrow$) | 下自旋 ($\downarrow$) |
|---|---|---|
| 单电子特征均值 (Single-electron) |
\(g^{\uparrow, l} = \frac{1}{n^{\uparrow}} \sum_{m=1}^{n^{\uparrow}} h_m^l\) | \(g^{\downarrow, l} = \frac{1}{n^{\downarrow}} \sum_{m=1}^{n^{\downarrow}} h_m^l\) |
| 双电子特征均值 (Two-electron, 含电子 $i$) |
\(f_i^{\uparrow, l} = \frac{1}{n^{\uparrow}} \sum_{m=1}^{n^{\uparrow}} h_{im}^l\) | \(f_i^{\downarrow, l} = \frac{1}{n^{\downarrow}} \sum_{m=1}^{n^{\downarrow}} h_{im}^l\) |
得到这些全局环境特征后,网络将它们与电子 $i$ 自身的当前特征拼接在一起,作为一个巨大的向量输入到一个标准的线性层(带有激活函数)中。单电子流的更新: \(f_i^l = \left[ h_i^l \;;\; g^{\uparrow, l} \;;\; g^{\downarrow, l} \;;\; f_i^{\uparrow, l} \;;\; f_i^{\downarrow, l} \right]\) \(h_i^{l+1} = \tanh \left( W^l f_i^l + b^l \right) + h_i^l \quad \text{(残差连接)}\)
Ferminet独具匠心的一点是,为了控制计算复杂度,双电子流的更新不需要从单电子流接收信息(单向哺育),也不跨电子对进行复杂的交叉聚合。它只对自己进行线性变换: \(h_{ij}^{l+1} = \tanh \left( V^l h_{ij}^l + c^l \right) + h_{ij}^l\)
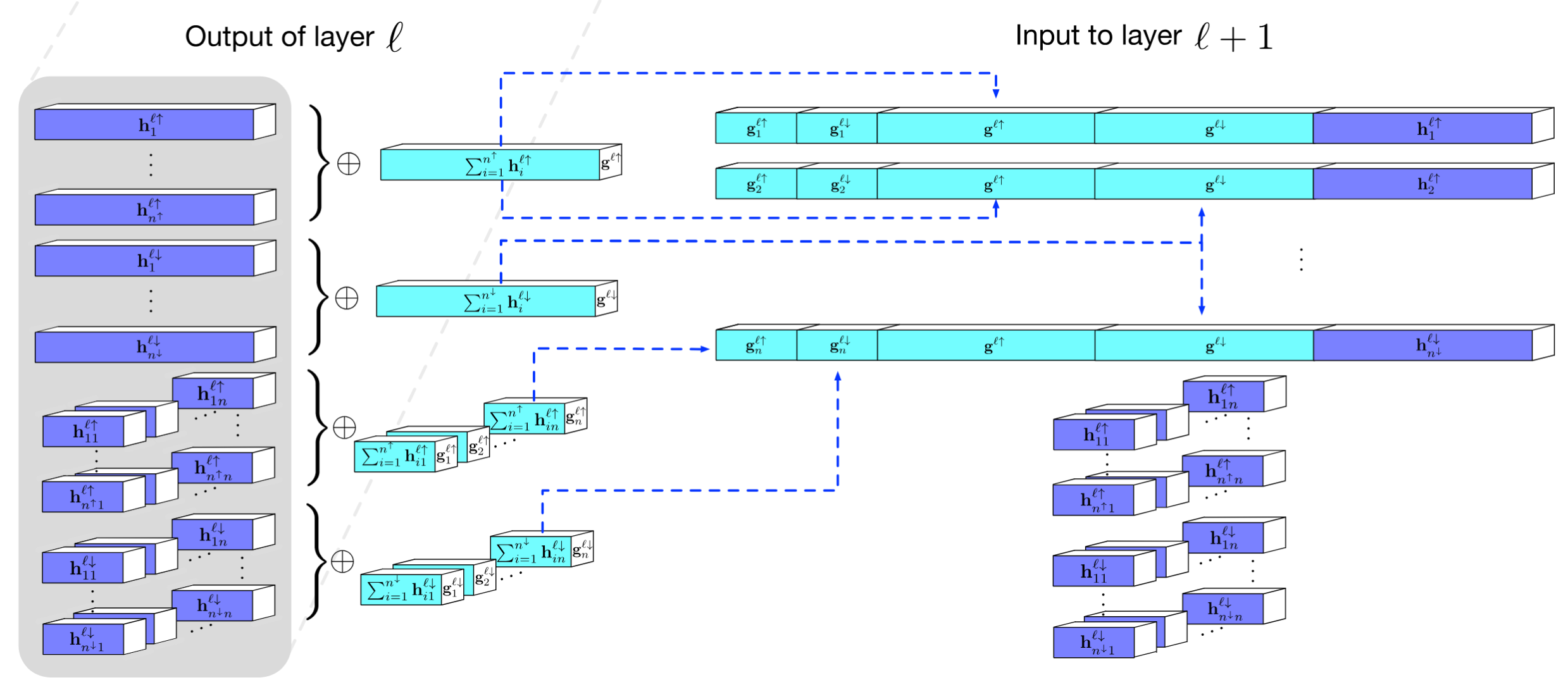
1.3 Output Layer
经过Hidden Layer的层层变换后,我们将在最后把所有单电子信息转化为Slater行列式中的单电子波函数,Ferminet网络的最后一层输出会被乘以一个各向异性的指数衰减包络函数 :
\[\phi_{i}^{k\alpha}(r_j^\alpha; \{r_{/j}\}) = \underbrace{\left( w_i^{k\alpha} \cdot h_j^{L\alpha} + g_i^{k\alpha} \right)}_{\text{网络特征投影}} \times \underbrace{\sum_{m} \pi_{im}^{k\alpha} \exp\left(-| \Sigma_{im}^{k\alpha} (r_j^\alpha - R_m) |\right)}_{\text{物理边界包络}}\]该设计的精髓在于通过参数 $\Sigma$ 和 $\pi$ 学习电子远离原子核时的行为,物理上严格保证了当电子远离原子核时,波函数能正确衰减到 0(边界条件)。
$\phi_{i}^{k\alpha}(r_j^\alpha; {r_{/j}})$这个形式说明每个单电子轨道方程的位置只与$r_j^\alpha$有关,当其他坐标${r_{/j}}$进行交换时其位置维持不变。此即为Hidden Layer中置换等变性的体现。由此保证了Slater行列式能够真正实现置换反对称性。
\[\Psi_{\text{single}} = \det[\mathbf{A}^\uparrow] \det[\mathbf{A}^\downarrow]\]理论上,只需要单一个($K=1$)广义斯拉特行列式,只要里面的神经网络无限宽、无限深,就足以完美逼近任何形式的费米子基态波函数。但从图例中可以看到我们其实从同一组单电子流特征向量中提取了多个行列式,然后再进行线性组合
\[\Psi_{\text{total}} = \sum_{k=1}^K \omega_k \det[\mathbf{A}_k^\uparrow] \det[\mathbf{A}_k^\downarrow]\]这么写当然也是满足反对称性。其主要的工程思想是在不怎么增加计算开销的前提下进一步提升网络深度。至于能提升什么程度,我持保守态度(
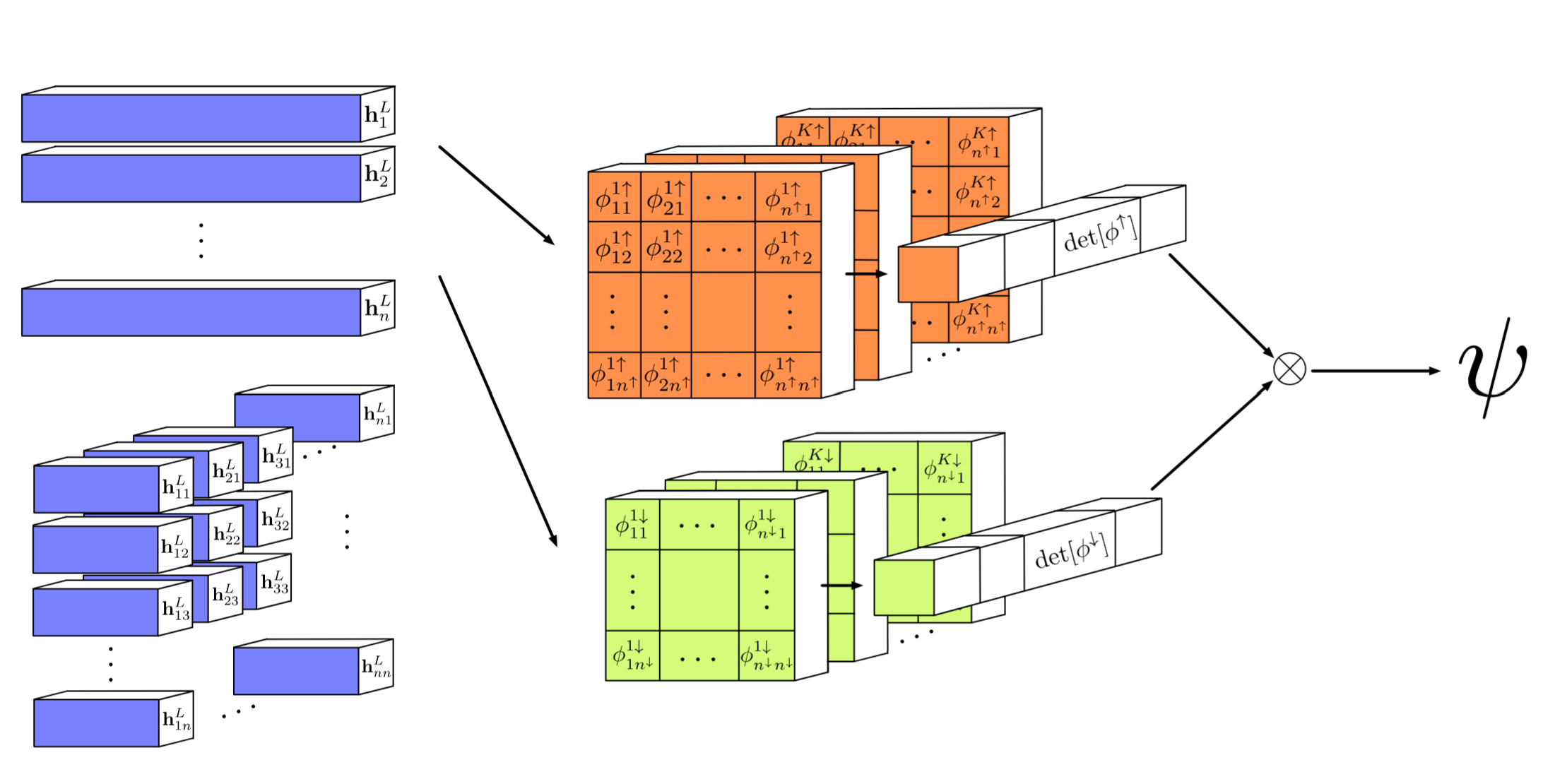
最后可以参考一下论文的架构流程总结

2. 网络拟合策略
2.1 梯度表达式计算
现在我们有了一个看似非常合理的架构,当务之急就是怎么通过VMC(在神经网络里就是梯度下降)的手段把拟设参数优化到最佳,也就是最小化体系多电子波函数的能量期望值 $\mathcal{L}(\theta)$ :
\[\mathcal{L}(\theta) = \frac{\langle\psi_{\theta}|\hat{H}|\psi_{\theta}\rangle}{\langle\psi_{\theta}|\psi_{\theta}\rangle} = \frac{\int dX \psi_{\theta}^*(X)\hat{H}\psi_{\theta}(X)}{\int dX \psi_{\theta}^*(X)\psi_{\theta}(X)}\]令 $p_\theta(X) = \frac{\psi_\theta^2(X)}{\int \psi_\theta^2(X) dX}$,并引入局部能量(Local Energy) $E_L(X) = \frac{\hat{H}\psi_\theta(X)}{\psi_\theta(X)}$。此时,损失函数可以写为对 $p_\theta(X)$ 的期望值:\(\mathcal{L}(\theta) = \int p_\theta(X) E_L(X) dX = \mathbb{E}_{p_\theta(X)}[E_L(X)]\)
现在我们对参数 $\theta$ 求梯度。 \(\nabla_\theta \mathcal{L} = \int \left[ \nabla_\theta p_\theta(X) \right] E_l(X) dX + \int p_\theta(X) \left[ \nabla_\theta E_l(X) \right] dX\)
来看第二项 $\int p_\theta(X) \nabla_\theta E_l(X) dX$。将 $p_\theta(X)$ 和 $E_l(X)$ 的定义代入: \(\int p_\theta(X) \nabla_\theta E_l(X) dX = \frac{1}{\int \psi_\theta^2 dX} \int \psi_\theta^2 \nabla_\theta \left( \frac{\hat{H}\psi_\theta}{\psi_\theta} \right) dX\)
根据商的求导法则,括号内部为 $\frac{(\nabla_\theta \hat{H}\psi_\theta)\psi_\theta - (\hat{H}\psi_\theta)(\nabla_\theta \psi_\theta)}{\psi_\theta^2}$。将其与外面的 $\psi_\theta^2$ 约去,得到: \(\frac{1}{\int \psi_\theta^2 dX} \int \left[ \psi_\theta \hat{H} (\nabla_\theta \psi_\theta) - (\hat{H}\psi_\theta) \nabla_\theta \psi_\theta \right] dX\)
因为哈密顿量 $\hat{H}$ 是厄米算符(Hermitian),满足 $\int \psi \hat{H} \phi dX = \int (\hat{H}\psi) \phi dX$。因此: \(\int \psi_\theta \hat{H} (\nabla_\theta \psi_\theta) dX = \int (\hat{H}\psi_\theta) \nabla_\theta \psi_\theta dX\)
这意味着上面括号内的两项积分后能够完全抵消 \(\int p_\theta(X) \nabla_\theta E_l(X) dX = 0\)
所以,损失函数的梯度完全取决于概率分布本身随参数的变化
\[\nabla_\theta \mathcal{L} = \int \left[ \nabla_\theta p_\theta(X) \right] E_l(X) dX\]由于我们无法直接从 $\nabla_\theta p_\theta(X)$ 中采样,需要将其重新转化为关于 $p_\theta(X)$ 的期望形式。这里使用一个微积分技巧: $\nabla_\theta p_\theta(X) = p_\theta(X) \nabla_\theta \log p_\theta(X)$ ,代入上式:
\[\nabla_\theta \mathcal{L} = \int p_\theta(X) \nabla_\theta \log p_\theta(X) E_l(X) dX = \mathbb{E}_{p(X)} [E_l(X) \nabla_\theta \log p_\theta(X)]\]因为 $p_\theta(X) = \frac{\psi_\theta^2(X)}{Z(\theta)}$(其中 $Z(\theta) = \int \psi_\theta^2 dX$),取对数得:
\[\log p_\theta(X) = 2 \log |\psi_\theta(X)| - \log Z(\theta)\]求梯度得: \(\nabla_\theta \log p_\theta(X) = 2 \nabla_\theta \log |\psi_\theta(X)| - \nabla_\theta \log Z(\theta)\)
左右两边取期望(对 $\int p_\theta(X)dX=1$ 两边求导,容易知道 $\mathbb{E}{p(X)}[\nabla\theta \log p_\theta(X)] = 0$ ),由此可得恒等式:
\[\nabla_\theta \log Z(\theta) = 2 \mathbb{E}_{p(X)}[\nabla_\theta \log |\psi_\theta(X)|]\]代回后得到: \(\nabla_\theta \log p_\theta(X) = 2 \left( \nabla_\theta \log |\psi_\theta(X)| - \mathbb{E}_{p(X)}[\nabla_\theta \log |\psi_\theta(X)|] \right)\)
将这个式子代回梯度的期望表达式中:
\[\nabla_\theta \mathcal{L} = 2 \cdot \mathbb{E}_{p(X)} \left[ E_l(X) \left( \nabla_\theta \log |\psi_\theta(X)| - \mathbb{E}_{p(X)}[\nabla_\theta \log |\psi_\theta(X)|] \right) \right]\]继续转化 \(\nabla_\theta \mathcal{L} = 2 \left( \mathbb{E}_{p(X)} \left[ E_l(X) \nabla_\theta \log |\psi_\theta(X)| \right] - \mathbb{E}_{p(X)}[E_l(X)] \cdot \mathbb{E}_{p(X)}[\nabla_\theta \log |\psi_\theta(X)|] \right)\)
不难注意到这其实就是协方差的形式
\[\nabla_\theta \mathcal{L} = 2 \cdot \text{Cov}_{p(X)} \left( E_l(X), \nabla_\theta \log |\psi_\theta(X)| \right)\]根据统计学中协方差的性质:$\mathbb{E}[AB] - \mathbb{E}[A]\mathbb{E}[B] = \mathbb{E}[(A - \mathbb{E}[A])B] = \mathbb{E}[A(B - \mathbb{E}[B])]$,我们可以最终得到论文中工程实用的形式(原文中差了个系数$2$,没有本质差别)
\[\nabla_\theta \mathcal{L} = 2 \cdot \mathbb{E}_{p(X)} \left[ \left( E_l(X) - \mathbb{E}_{p(X)}[E_l(X)] \right) \nabla_\theta \log |\psi_\theta(X)| \right]\]工程上,我们可以在代码中显式构建以下标量函数:
\[\mathcal{L}_{\text{surr}}(\theta) = \frac{1}{M} \sum_{m=1}^{M} \left( E_l(X_m) - \bar{E}_l \right) \cdot \log |\psi_\theta(X_m)|^2\]当我们直接对 L_surr 调用自动微分 jax.grad 时,框架根据链式法则对 $\theta$ 求导,吐出的梯度刚好就是:
\(\nabla_\theta \mathcal{L}_{\text{surr}} = \frac{2}{M} \sum_{m=1}^{M} \left( E_l(X_m) - \bar{E}_l \right) \nabla_\theta \log |\psi_\theta(X_m)|\)
利用MCMC采样使样本点符合$p(X)$分布后,只要样本数够多,我们就能很轻松得到这个梯度数值。
2.2 自然梯度下降与Fisher矩阵
论文中没有采用传统的梯度下降和优化器(如Adam) \(\theta_{t+1} = \theta_t - \eta \cdot \nabla_\theta \mathcal{L}\)
因为多体波函数这玩意自带Cusp,在电子-电子,电子-原子核重叠时波函数变化很剧烈,所以容易无法正常收敛。这要求我们用一些更先进的梯度下降算法。比如自然梯度下降(NGD)。
直观理解一下,考虑两对高斯分布:
-
左侧:$N(0,0.2)$与$N(1,0.2)$
-
右侧:$N(0,10)$与$N(1,10)$
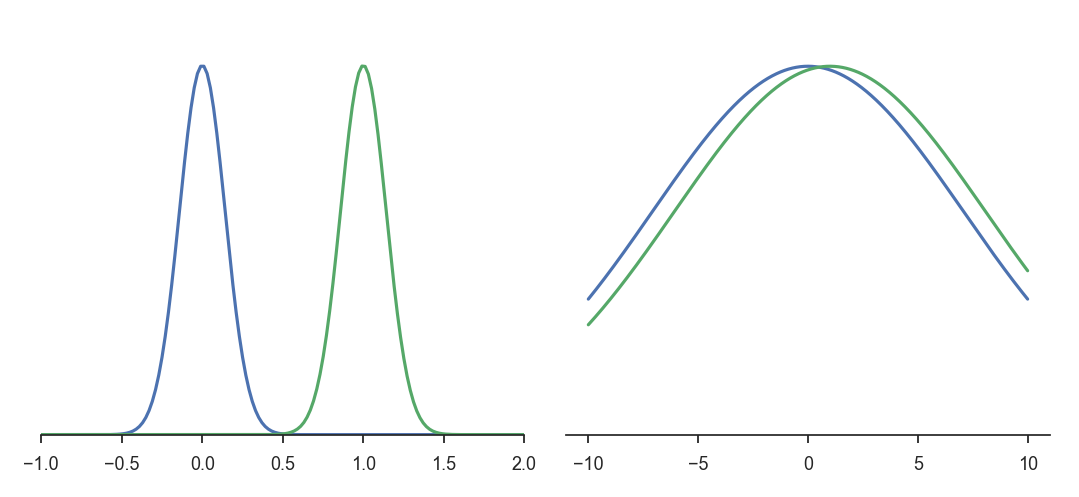
两组分布在参数空间中的欧几里得距离相同,但右侧分布显然更接近。两组分布在参数空间中的欧几里得距离相同,但右侧分布显然更接近。这说明参数空间的欧几里得距离无法正确刻画概率分布的相似性。为此我们可以采用信息论中经典的 KL 散度(Kullback-Leibler Divergence)来严格衡量这两个概率分布之间的实质物理距离。 \(D_{\text{KL}}(p(x; \theta) \parallel q(x; \theta)) = \int p(x; \theta) \log \frac{p(x; \theta)}{q(x; \theta)} dx\)
对其进行泰勒展开 \(D_{\text{KL}}(p(x; \theta) \parallel p(x; \theta + d\theta)) = \int p(x; \theta) \log \frac{p(x; \theta)}{p(x; \theta + d\theta)} dx\)
可以证明零阶项和一阶项都是0,即 \(D_{\text{KL}}(p(x; \theta) \parallel p(x; \theta + d\theta)) \approx \frac{1}{2} d\theta^T \mathcal{F} d\theta\)
其中$\mathcal{F}$为Fisher矩阵,表达式为
\[\mathcal{F} = \mathbb{E}_{x \sim p_\theta(x)} \left[ \nabla_\theta \log p_\theta(x) \cdot \nabla_\theta \log p_\theta(x)^T \right]\] \[\mathcal{F}_{ij} = \mathbb{E}_{x \sim p(x; \theta)} \left[ \frac{\partial \log p(x; \theta)}{\partial \theta_i} \cdot \frac{\partial \log p(x; \theta)}{\partial \theta_j} \right]\]在数学上,“最速下降”的定义是:在给定一个微小的步长约束下,能让损失函数下降最快的那个方向。
-
标准梯度下降(SGD):限制的是参数的欧氏距离($|d\theta|2 \le \epsilon$),也就是代码中写死的步长限制。在这个标准下,最速下降方向就是负梯度方向 $-\nabla\theta L(\theta)$。
-
自然梯度下降(NGD):限制的是概率分布之间的KL散度距离($D_{KL}(P_\theta | P_{\theta+d\theta}) \le \epsilon$),相当于在限制步长之前对空间做了一个变化,平衡了各方向的步长权重。在这个标准下,最速下降方向变成了 $-\mathcal{F}^{-1}\nabla_\theta L(\theta)$。
因此,自然梯度下降的更新公式为: \(\theta_{t+1} = \theta_t - \eta \mathcal{F}^{-1} \nabla_\theta L(\theta)\)
下面再对Fisher矩阵进行一些简化,首先根据定义展开对数概率 $\log p_\theta(X)$
\[\log p_\theta(X) = \log \left( \frac{\psi_\theta^2(X)}{Z(\theta)} \right) = 2 \log |\psi_\theta(X)| - \log Z(\theta)\]对参数 $\theta_i$ 求偏导数: \(\frac{\partial \log p_\theta(X)}{\partial \theta_i} = 2 \frac{\partial \log |\psi_\theta(X)|}{\partial \theta_i} - \frac{\partial \log Z(\theta)}{\partial \theta_i}\)
为了书写简明,定义波函数关于参数的对数导数(即分数函数 Score Function)为$\mathcal{O}_i(X)$: \(\mathcal{O}_i(X) \equiv \frac{\partial \log |\psi_\theta(X)|}{\partial \theta_i}\)
现在处理右边的 $\log Z(\theta)$ 微分项 \(\frac{\partial \log Z(\theta)}{\partial \theta_i} = \frac{1}{Z(\theta)} \frac{\partial Z(\theta)}{\partial \theta_i} = \frac{1}{\int \psi_\theta^2(X) dX} \int \frac{\partial \psi_\theta^2(X)}{\partial \theta_i} dX\)
由于 $\frac{\partial \psi_\theta^2(X)}{\partial \theta_i} = 2 \psi_\theta(X) \frac{\partial \psi_\theta(X)}{\partial \theta_i} = 2 \psi_\theta^2(X) \frac{\partial \log |\psi_\theta(X)|}{\partial \theta_i}$,代入上式得: \(\frac{\partial \log Z(\theta)}{\partial \theta_i} = \int \left( \frac{\psi_\theta^2(X)}{\int \psi_\theta^2(X) dX} \right) \cdot 2 \mathcal{O}_i(X) dX = 2 \cdot \mathbb{E}_{X \sim p_\theta} \left[ \mathcal{O}_i(X) \right]\)
将该结果带回,我们得到了未归一化波函数对数概率梯度的精确表达式: \(\frac{\partial \log p_\theta(X)}{\partial \theta_i} = 2 \left( \mathcal{O}_i(X) - \mathbb{E}_{X \sim p_\theta}[\mathcal{O}_i(X)] \right)\)
代入Fisher矩阵的定义式中:
\[\mathcal{F}_{ij} = \mathbb{E}_{X \sim p_\theta} \left[ 2 \left( \mathcal{O}_i(X) - \mathbb{E}[\mathcal{O}_i] \right) \cdot 2 \left( \mathcal{O}_j(X) - \mathbb{E}[\mathcal{O}_j] \right) \right]\] \[\mathcal{F}_{ij} = 4 \cdot \left( \mathbb{E}_{X \sim p_\theta} [\mathcal{O}_i(X) \mathcal{O}_j(X)] - \mathbb{E}_{X \sim p_\theta}[\mathcal{O}_i(X)] \mathbb{E}_{X \sim p_\theta}[\mathcal{O}_j(X)] \right)\]考虑到前面的系数最后都可以合并到学习率$\eta$中,记$\tilde{\mathcal{O}}_i(X) = \mathcal{O}_i(X) - \mathbb{E}[\mathcal{O}_i]$,总Fisher矩阵可写为
\[\mathcal{F} = \mathbb{E}_{X \sim p_\theta} \left[ \tilde{\mathbf{\mathcal{O}}}(X) \tilde{\mathbf{\mathcal{O}}}(X)^T \right]\]2.3 Kronecker-factored Approximate Curvature (KFAC)
理论很美好,但这个东西在工程上问题不小。如果模型有 $N$ 个参数,Fisher矩阵 $F$ 的大小就是 $N \times N$。计算 $F$ 的逆矩阵 $F^{-1}$ 的时间复杂度达 $O(N^3)$,内存消耗 $O(N^2)$,这在工程上是无法直接承受的。
下面介绍一下NGD的核心优化技术KFAC,具体来说其包含两个核心假设
-
假设一:层间独立假设
KFAC 认为,第 $l$ 层的参数和第 $l+1$ 层的参数,它们之间的二阶相关性可以忽略不计。这样一来,巨大的费舍尔矩阵 $F$ 就变成了一个分块对角矩阵。每一层对应一个独立的子块 $F_l$。
-
假设二:输入与梯度的克罗内克积近似
对于某一层,前向传播的输入(激活值)为 $a$,后向传播传回来的激活值梯度(损失对该层输出的导数)为 $s$。那么该层权重的梯度可以表示为 $g = s a^T$。
这一层的Fisher矩阵块 $F_l$ 本质上是:\(F_l = \mathbb{E}[g g^T] = \mathbb{E}[(s a^T)(s a^T)^T]\) KFAC 提出了一个核心近似:假设前向的激活值 $a$ 和反向的梯度 $s$ 是统计独立的。基于这个独立性假设,期望的积可以拆分为积的期望(克罗内克积 $\otimes$): \(F_l \approx \mathbb{E}[a a^T] \otimes \mathbb{E}[s s^T] = A \otimes S\)
克罗内克积的定义如下:\(A \otimes B = \begin{bmatrix} a_{11}B & a_{12}B \\ a_{21}B & a_{22}B \end{bmatrix}\)
注意到克罗内克积有一个独特的数学性质 \((A \otimes S)^{-1} = A^{-1} \otimes S^{-1}\)
正是这个方程大大减少了整个求逆的计算量。也就是说把大矩阵的求逆看作是两个小矩阵的逆的克罗内克积。
具体到Ferminet中,我们单独考察 FermiNet 内部的某一个特定的线性全连接层(第 $l$ 层)。令该层的输入(即上一层的激活值)为单样本列向量 $a \in \mathbb{R}^{d_{\text{in}}}$,当前的权重矩阵为 $W \in \mathbb{R}^{d_{\text{out}} \times d_{\text{in}}}$。该层在激活前的输出向量为 $s \in \mathbb{R}^{d_{\text{out}}}$:
\[e = W a\]在反向传播过程中,定义损失函数(此处为波函数对数项)关于未激活输出 $s$ 的敏感度(一阶梯度)列向量为:
\[s = \nabla_e \log |\psi_\theta(X)| \in \mathbb{R}^{d_{\text{out}}}\]根据多元微积分的一阶全微分形式,损失函数关于权重矩阵中任意单个元素 $W_{ij}$(第 $i$ 行,第 $j$ 列)的偏导数为:
\[\mathcal{O}_{W_{ij}} = \frac{\partial \log |\psi_\theta(X)|}{\partial W_{ij}} = \frac{\partial \log |\psi_\theta(X)|}{\partial e_i} \cdot \frac{\partial e_i}{\partial W_{ij}} = s_i \cdot a_j\]也可以写成矩阵形式,它恰好构成敏感度向量 $e$ 与激活向量 $a$ 的外积:
\[\mathbf{\mathcal{O}}_W = s a^T \in \mathbb{E}^{d_{\text{out}} \times d_{\text{in}}}\]根据线性代数性质 $\text{vec}(u v^T) = v \otimes u$,可将拉平后的整层梯度长向量写为:
\[\mathbf{\mathcal{O}}_{\text{vec}(W)} = \text{vec}(s a^T) = a \otimes s\]考虑到未归一化波函数修正要求,我们对输入和反向梯度分别进行均值中心化:
\[\tilde{a} = a - \mathbb{E}_{X \sim p_\theta}[a], \quad \tilde{s} = s - \mathbb{E}_{X \sim p_\theta}[s]\]该层权重对应的中心化梯度长向量便可以近似表示为:
\[\tilde{\mathbf{\mathcal{O}}}_{\text{vec}(W)} \approx \tilde{a} \otimes \tilde{s}\] \[\mathcal{F}_l \approx \mathbb{E}_{X \sim p_\theta} \left[ (\tilde{a} \otimes \tilde{s}) (\tilde{a} \otimes \tilde{s})^T \right]\]根据克罗内克积的转置代数性质 $(A \otimes B)^T = A^T \otimes B^T$,上式可变形为:
\[\mathcal{F}_l \approx \mathbb{E}_{X \sim p_\theta} \left[ (\tilde{a} \otimes \tilde{s}) (\tilde{a}^T \otimes \tilde{s}^T) \right]\]再引入克罗内克积与矩阵乘法的混合乘法性质,即 $(A \otimes B)(C \otimes D) = (AC) \otimes (BD)$。我们将期望符号内部的两项进行合并:
\[\mathcal{F}_l \approx \mathbb{E}_{X \sim p_\theta} \left[ (\tilde{a} \tilde{a}^T) \otimes (\tilde{s} \tilde{s}^T) \right]\]根据KFAC核心假设二,前向激活值的协方差变动与反向敏感度的协方差变动在统计学上是近似独立的,即满足$\mathbb{E}[XY] = \mathbb{E}[X]\mathbb{E}[Y]$,我们将期望算子推入克罗内克积的内部:
\[\mathcal{F}_l \approx \mathbb{E}_{X \sim p_\theta} \left[ \tilde{a} \tilde{a}^T \right] \otimes \mathbb{E}_{X \sim p_\theta} \left[ \tilde{s} \tilde{s}^T \right]\]我们现在单独定义这两个拆分出来的、维度较小的自协方差矩阵:
\[\mathbf{A} = \mathbb{E}_{X \sim p_\theta} \left[ \tilde{a} \tilde{a}^T \right] = \mathbb{E}[a a^T] - \mathbb{E}[a]\mathbb{E}[a]^T \quad \in \mathbb{R}^{d_{\text{in}} \times d_{\text{in}}}\] \[\mathbf{S} = \mathbb{E}_{X \sim p_\theta} \left[ \tilde{s} \tilde{s}^T \right] = \mathbb{E}[s s^T] - \mathbb{E}[s]\mathbb{E}[s]^T \quad \in \mathbb{R}^{d_{\text{out}} \times d_{\text{out}}}\]至此,原先大到无法计算的层级费希尔矩阵块 $\mathcal{F}_l$,被完美因式分解为两个小矩阵的克罗内克积:\(\mathcal{F}_l \approx \mathbf{A} \otimes \mathbf{S}\)
梯度下降因此可写为
\[\text{vec}(\Delta W) = - \eta \cdot \left( \mathbf{A}^{-1} \otimes \mathbf{S}^{-1} \right) \cdot \text{vec}(\nabla_W \mathcal{L})\]利用恒等式
\[(A \otimes B) \cdot \text{vec}(C) = \text{vec}(B \cdot C \cdot A^T)\]得到最终工程上的计算公式。
\[\Delta W = - \eta \cdot \mathbf{S}^{-1} \cdot (\nabla_W \mathcal{L}) \cdot \mathbf{A}^{-1}\]当然真实的工程计算大概率还得再加一点细节,这里就点到为止。
3. 结果分析
这部分就不写了,神经网络这玩意懂得都懂,论文中肯定只会拿具有说服力的结果,自己对着论文复述一遍也没有意义。
不过不可否认的是这个网络本身的确具有很强的启发意义,通读一遍后自己收获不少。这也算是自己的第一篇论文精读笔记,希望能够坚持。
果然还是应该抓紧时间学习更多才行。
[1] 好吧,其实还是在复述。



